
一定許多人都有過這種經驗。
收到朋友傳來的檔案,點開來以後卻顯示一堆看不懂的文字,這就是俗稱的「亂碼」。從亂碼這個問題當作出發點,這篇我想帶大家以比較白話的方式去看為什麼會產生這個問題,以及這個問題該如何解決,目的是想讓沒什麼技術背景的人,也能理解「編碼」到底是什麼,以及一些重要的細節。
我們就從一個小故事開始吧,主角是好久沒出現的小明,地點是學校,時間是 2000 年,一個智慧型手機還沒流行的年代。
上課無聊不用功,想盡辦法來溝通
小明是一位國中二年級的學生,沒錯,就是俗稱的中二。
他在上課的時候總是不專心,聽不進去老師在講什麼,也不想聽進去。感到無聊的他,想要透過跟同學聊天來打發時間。可是這是在上課,又能跟誰聊天呢?
在那個傳簡訊一封要三塊的年代,傳紙條顯然是個更超值且合理的選擇。
班上有另外一位叫做小美的同學,爸爸是美國人,媽媽是台灣人,從小在美國長大,小四以後才回來台灣唸書,因此英文比中文還好。
小美就坐在小明的旁邊,也是小明的麻吉,因此傳紙條的首選顯然就是小美了。
可是,在紙條上面用文字聊天並不是個好方法,因為被老師抓到的話就直接掰掰了,小則口頭警告,大則記警告,小明不想因為傳紙條這種事情而被通知家長。
幸運的是,數學老師跟其他老師不同。就算被抓到在傳紙條,只要紙條上面寫的是「一連串的數字」,數學老師就會覺得你在認真學數學,所以不會管你。雖然數學老師時常請假,但在這點上還是挺有原則的。
於是,聰明的小明想到了跟你一樣的事情:
「那我把傳紙條的內容改成數字不就好了嗎?」
紙條上頭寫滿字,內容必須是數字
要怎麼把原本想溝通的內容從文字轉成數字呢?
有一個直覺、暴力但是好用的方法,那就是把每一個英文字母(他跟小美都用英文溝通為主,這樣對小美來說比較快)都換成一個數字。
於是,小明做出了以下的表格:
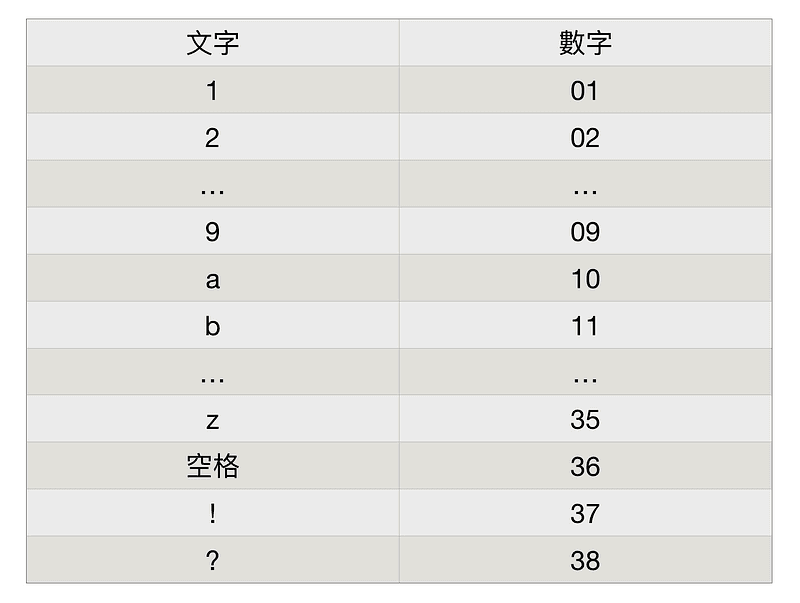
他把數字+英文字母+一些符號都對應到了一個數字,並且把這個表格在下課時拿給了小美,要他背起來,背起來以後看見數字就可以知道文字是多少。
例如說小明想傳「hi」,就寫成「1718」,小美看到之後就知道這是 hi,想傳更複雜的「good job!」,就是「162424133619241138」,透過這張文字數字轉換表,就可以在符合數學老師的規則底下順利溝通,光明正大在上課的時候傳紙條聊天。
看著小明跟小美在上課的時候聊得這麼開心,英文不好的阿猛很不是滋味。
英文不好不用跑,從頭再造一張表
阿猛也想在上課的時候光明正大傳紙條,但是他沒辦法沿用小明的這張表格,因為他英文超爛。
於是,效仿著小明的方法,阿猛拿起了國文課團購的字典,想到了一個妙招,那就是用字典的頁數加上「出現在這頁的第幾個字」,一樣也可以達到原本表格「一個文字對到一個數字」的效果。
例如說 31,就代表第三頁的第一個字,52 就代表第五頁出現的第二個字,但問題來了,那 111 怎麼辦?這到底是代表第一頁的第十一個字,還是第十一頁的第一個字?
為了解決這個問題,阿猛制定了一個規範,因為這本字典最多只有到 2100 頁,而每一頁最多只會有 40 個字,所以格式應該要是 xxxxyy,xxxx 代表頁數,沒有四位就補零,yy 代表第幾個字。
所以第 1頁的第 3 個字,就會是 000103,第 1223 頁的第 17 個字,就是 122317。
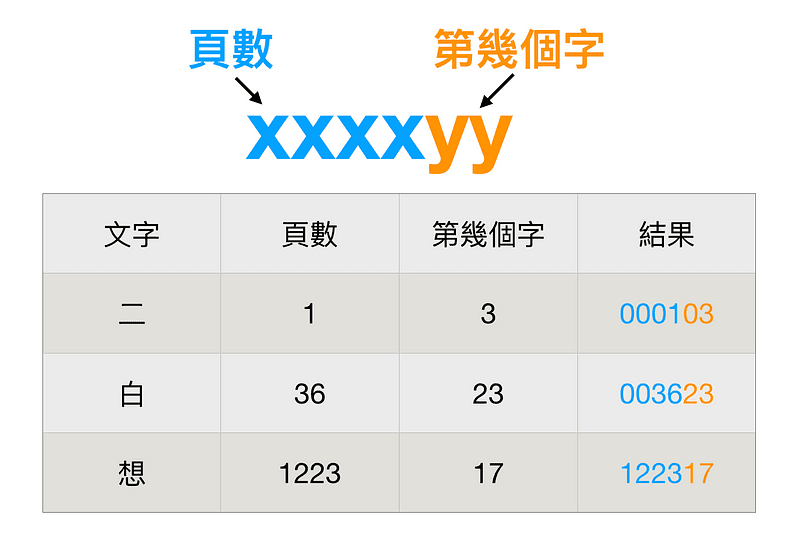
透過這樣的編碼方式,阿猛成功地把常見的文字都編碼成數字,並且利用這套方式跟其他同學溝通。一瞬間,整個班上都流行起這樣的方法,上課時紙條飛來飛去,而數學老師則是很開心地點點頭,稱讚大家真是用功向學。
直到,這一切的平靜被一張誤會的紙條給打破。
紙條傳錯起爭議,整合表格勢必行
有天,小明收到一張紙條,上面寫著的是「153012203037」,根據他一開始做的英文轉換表,得到的結果是:「fucku!」,小明嚇到了,想說他又沒有跟其他同學結仇,為什麼要特別傳一張紙條來罵他?
看到他驚訝的表情,傳紙條給他的同學在下課後來找他澄清:
欸不是啦,我是寫中文啦,那是「打咖」的意思
153012 是「打」,203037 是「咖」,在中文字典上面確實是這樣沒錯。
同時間,也有其他同學碰到類似的狀況,怎麼收到的紙條解讀完以後是「jefjsq」,這是完全看不懂的亂碼啊!下課後才發現應該是要用中文來解讀那些數字,而不是用英文。
小明意識到了問題的嚴重性,那就是現在有兩套編碼系統同時在使用,而這兩套系統會產生混淆。如果你用中文系統去解讀英文的數字,或是相反過來,都只會解讀出無意義的東西(或是像小明那樣很衰的剛好是完全不同的意思)。
於是小明有了一個想法:「我們把中英文都整合在同一張表格吧!把所有的文字都整合在一張表格,就不會混淆了!」
整合後的表格就跟之前類似,只是稍微調整了一下。
小明把 0000 這前四碼作為「英文編碼」的意思,就可以快速整合兩種編碼系統。舉例來說,原本英文的 a 是 10,在新系統裡面就變成 000010,而原本的中文因為本來就不會用到 0000 這個頁面,所以可以保留跟之前一樣的規則。
如此一來,幾乎每一個六位數的數字都有對應的文字,而每一個文字也都有一個對應的數字,大家只要看到前四碼是 0,就會知道這是英文,反之則是中文。
從此以後大家就過著開心快樂的生活,傳紙條傳得不亦樂乎…嗎?
還沒有,還差一點。
紙張太小塞不下,調整編碼加容量
調整成新的編碼方式以後,有許多平常都只用英文來溝通的同學們集體抱怨,本來只要兩個數字就能搞定的東西,怎麼突然變成六個了?
紙條小小一張,原本我可以寫 30 個英文字母的,現在只能寫 10 個字母,這樣太浪費空間了吧!
於是,小明被迫思考新的編碼方式,他左思右想,終於想到了一個好方法。
那就是,編碼不再以六個字母為一個單位,而是以三個字母為一個單位。
規則是這樣的,如果是英文字的話,就在第一位加上 0,例如說 a 本來是 10,現在要寫成 010,z 本來是 35,現在要寫成 035。
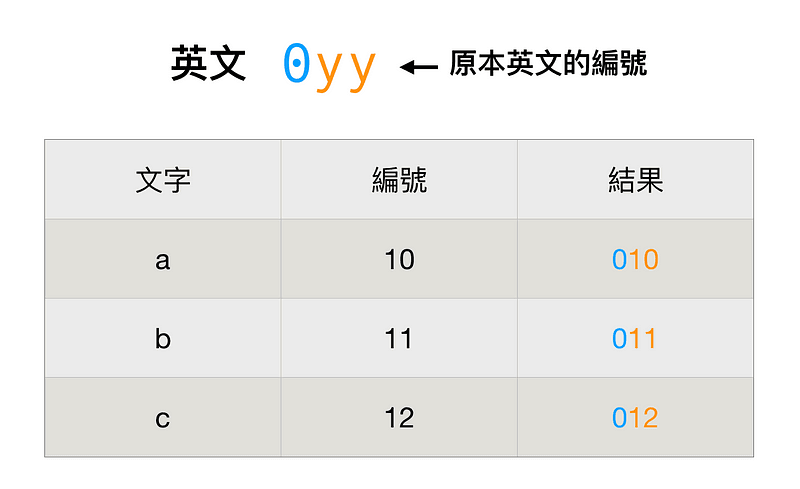
那中文呢?中文的話比較複雜一點。
因為現在一組編碼只有三個數字,如果我們的字典最多只到 99 頁的話,事情就好辦了,只要編成 1yy 9zz 就好,yy 代表頁數,zz 代表第幾個字。
例如說看到 138 913,就知道是「第 38 頁第 13 個字」。
但問題是這樣的方式沒辦法表示「第 1527 頁的第 13 個字」,因為 yy只有兩位,只能表達兩位數字。
因此,要表示 100 頁以上的資料,必須再多引入一組數字,像這樣:
2yy 3yy 9zz,yy 一樣代表的是頁數,zz 代表第幾個字,「第 1527 頁的第 13 個字」就會是 215 327 913。
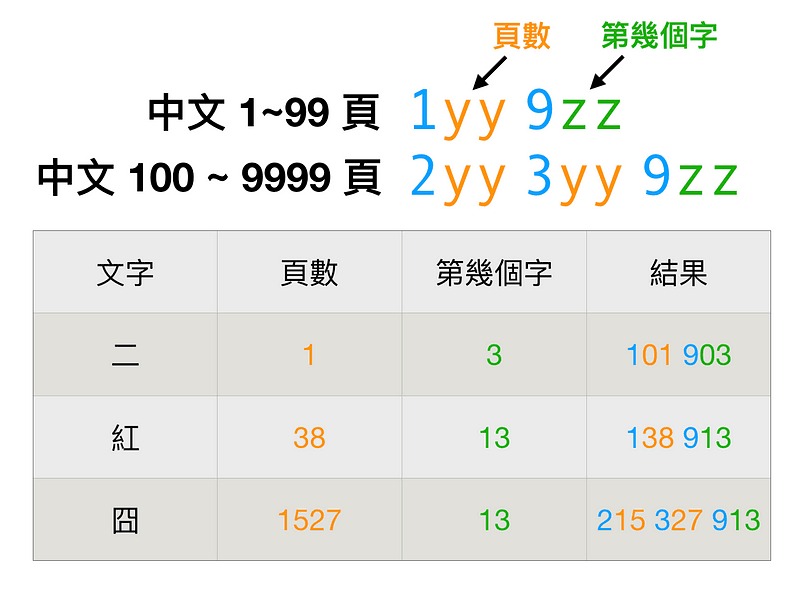
換句話說呢,小明把三個數字中的第一個數字,當作是一個「指示」,根據它是 0, 1, 2, 3, 9 的哪一種,就可以知道應該要用什麼樣的規則去解析它。
在這種編碼系統當中,最後編碼出來的東西長度是會變化的。
有些字只需要一組數字,例如說英文。有些字需要兩組數字,例如說出現在 1-99 頁的中文,而有些字需要三組數字,像是 100 頁以上的中文字。
這樣的好處是什麼?
最大的好處就是它節省了空間。在我們之前的版本中,無論是中文還是英文,每一個字就是需要 6 個數字。而在這個新的版本中,英文只需要 3 個,減少了一半的空間,而對 100 頁以上的中文來說則需要 9 個數字,雖然是原本的 1.5 倍,但其實常用的中文都出現在 100 頁以前,所以整體來說還是更有效率的。
調整成這個新的系統以後,對於常使用英文的同學來說大幅減少了紙張的消耗,因為要寫的數字變少了。而對那些用中文筆談的同學來說,其實影響不大,畢竟大部分都還是用常見的中文字在聊天,跟以前一樣只需要 6 個數字即可。
總結一下,小明跟他們同學們創造的這一套編碼系統其實是很完整的,功能包含:
- 成功符合了老師創造的規則,紙條上只有一連串的數字
- 涵蓋所有常用的字,而且未來可以再擴充
- 把每一個字對應到了一個獨一無二的數字
- 定義了該如何把數字轉成特定格式,讓其他同學方便解析又節省空間
就這樣,小明跟他的同學們靠著自己發明的編碼系統,快樂地度過了在學校的時光。但他們不知道的是,原來在好幾年前的真實世界中,就已經有過類似的概念了。
真實世界中的編碼
許多人應該都聽過一種說法,那就是「在電腦的眼中,所有的東西都只有 0 跟 1」,那你有沒有想過,在只有 0 跟 1 的世界中,該如何表示文字呢?
換句話說,該如何用數字來表示文字?
電腦科學家們對這個問題的解答與小明一樣:「建立一張轉換表!」
在 1960 年代,一個叫做 ASCII 的編碼系統(全名為 American Standard Code for Information Interchange,美國標準資訊交換碼)誕生了。它並不是最早的編碼系統(例如說更早還有個叫 FIELDATA 的東西),不過卻是早期使用的最廣泛的。
這個編碼系統就跟小明做的事情一樣,把每一個文字都對應到了一個數字:
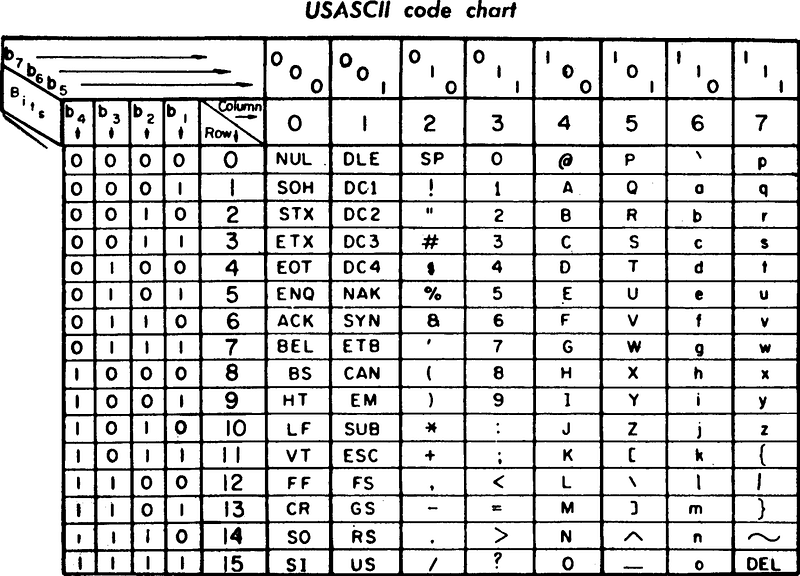
因為電腦中都是用只有 0 跟 1 的二進位來表示數字,所以這個表格才會有一堆 0 跟 1。舉例來說,英文字母大寫 B 的直排是 100,橫排是 0010,因此它的編碼就是 1000010,轉換成十進位的話是 66。
而與故事中不同的是,上面這張編碼表的前兩排有一堆看起來不是文字的東西,這些叫做控制字元(Control character),你可以簡單想成那些字不是給人看的,而是給電腦看的。
舉例來說,編號為 7(0000111)的是一個叫做 BEL 的字元,電腦讀到這個字元之後,就會發出嗶嗶的聲音。透過這些控制字元,你可以「控制」電腦的部分行為。
而歷史後來的發展就跟小明的經歷一樣,ASCII 在建立的時候只考慮到了美國常用的字母,那中文怎麼辦?韓文怎麼辦?
於是每個國家都有了自己的編碼系統,例如說台灣在 1980 年代就設計了一種叫做 Big5 的編碼系統,來涵蓋各種中文字。而日本、韓國或其他國家也都有各自的編碼系統。
而這種各自為政的狀況,導致的結果就跟小明的故事如出一轍,電腦在解讀一串數字的時候,如果用的編碼系統跟預期中的不同,就會產生出亂碼。舉例來說,今天你用 Big5 編碼系統去編碼「你好」,產生的可能是 12324470,但這串字被 ASCII 解讀後可能是「? $8」這四個字元。
所以,要讓電腦看懂一串文字,除了原始資料以外,還必須要有編碼資訊,否則電腦只能用猜的,例如說猜你這串資料看起來很像 Big5 的格式,就用 Big5 來解碼。
在 1980 年末的時候,出現了一群人想要來統一這個亂象,想要做出一個普遍的(universal)編碼系統,容納世界上所有的文字,統一了標準以後,就不會有亂碼產生了。
而這個編碼系統,就叫做 Unicode。
Unicode 做的第一件事情很簡單,就是把每一個文字都對應到一個數字,專有名詞叫做 code point。例如說中文字的「立」,對應到的數字就是 7ACB(會有英文是因為十六進位的緣故),前面加上 U+ 來表示 Unicode:

所以只要看到「U+7ACB」,就知道這代表的是「Unicode 中的 code point 7ACB」。
把每一個文字都對應到數字以後,還有最後一個問題要解決,那就是該怎麼儲存在電腦中。最簡單暴力的方法就是小明也用過的補零,把每一個文字都用 4 個 byte(32 bit)來存,最輕鬆最容易,這種編碼方式就叫做 UTF-32。
所以電腦一看到這個檔案的編碼是 UTF-32,就知道說它應該把資料分成每 32 個 bit 一組,然後用 Unicode 的 code point 去把數字還原成文字。
而 UTF-32 的缺點顯而易見,就是太浪費空間了。英文字為了向下相容以前的 ASCII 系統,code point 是跟 ASCII 一樣的。例如說 ASCII 中的 A 是 65,在 Unicode 中也會是 65,這樣使用 Unicode 來編碼的英文字在舊電腦中也可以正常顯示,這就叫做向下相容。
而 ASCII 只需要 8 個 bit 就可以存一個字,現在換成 UTF-32 要用 32 個 bit,直接變成四倍的空間,也太不划算了吧?
於是,就有了另外一種編碼方式,叫做 UTF-8,它代表的意思跟小明最後設計出來的編碼系統是一樣的,那就是「儲存文字的長度是會變化的」,底下是維基百科上給的轉換表格:
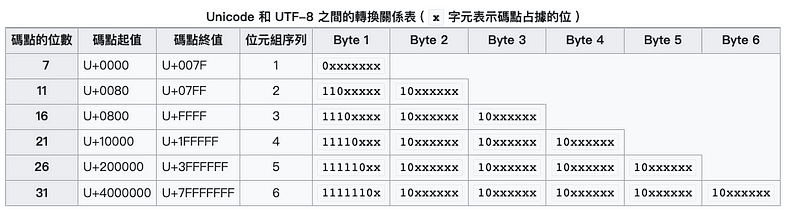
看起來很難懂對吧?但如果我跟你說,它其實就是這張表的進階版呢:
UTF-8 那張轉換表格在講的事情是一樣的,它是在定義說:「你本來的 code point 如果是 0 - 127,那就用一個 byte 來存就好。如果本來是 128 - 2047,就用兩個 byte 來存」。
而你會在表格中看到 Byte1、Byte2 最前面幾個數字是固定的,這就跟小明製作的表格一樣,目的是把前面最幾個數字當成「指示」。
舉例來說,電腦在看到一個 byte 的最左邊是 0 的時候,就知道這一個 byte 就代表一個字。在看到最左邊是 110 的時候,就知道這個 byte 要跟下一個 byte 一起看,才能表示完整的一個字。
就跟小明的表格一樣,最左邊是 0 代表是英文,最左邊是 1 代表它是 1-99 頁的中文,邏輯是完全一樣的。
而 UTF-8 的優點就是節省空間,與固定使用 32 bit 的 UTF-32 相比,對於常用的文字(英文)來說,只需要 8 個 bit 就好了。
因此現今,最廣泛使用的編碼方式就屬 UTF-8 為主了。
所以,亂碼到底是什麼?
亂碼就是你用 A 編碼系統來編碼,可是電腦卻用 B 系統來解碼,解出來的東西自然而然就會變成一堆看不懂的東西,就叫做亂碼。
現在基本上都是用同一種編碼系統,已經比較少看見亂碼了,但在十幾年前有些檔案是 Big5,此時如果用 UTF-8 來解讀,就會看見一堆亂碼,反之亦然。
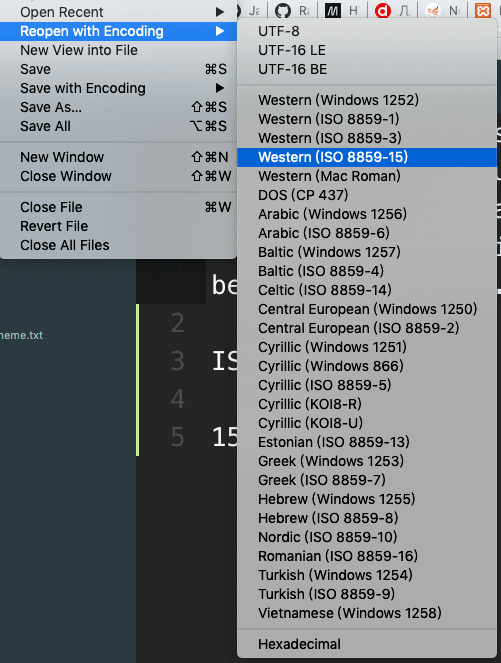
電腦在打開一個文字檔案的時候,會從檔案內容去猜測編碼,而有些文字編輯器也可以自己選擇要用什麼編碼來顯示,例如說我用的 Sublime:
而有些更有經驗的人,甚至能夠看見數字就大概猜出是什麼樣的編碼,例如說這篇:Re: [問題] 關於解碼的問題。
結語
複習一下這一篇裡面提到的概念:
- 要把文字儲存在電腦裡面時,必須要先編碼成數字
- ASCII 是一套用 7 個 bit 來儲存文字的編碼系統,只支援英文、符號跟一些控制字元
- Unicode 是一套容納了世界上所有文字的編碼系統,把每一個文字都對應到一個 code point,而實際儲存在電腦中又有不同的編碼方式。所以,只知道一個文字是用 Unicode 來編碼是沒用的,還需要知道怎麼儲存的
- 舉例來說,UTF-32 把每一個 code point 都用 32 個 bit 來存,簡單方便但是浪費空間
- 而 UTF-8 則是幫範圍不同的 code point 制定不同規則,用特定格式來儲存文字,有的用 8 個 bit 就好,有些會用到 32 個 bit,以常用的字來說,節省了不少空間
- 亂碼就是在儲存跟顯示時使用了不同的編碼系統,可能導致的狀況,只要改用同一個編碼系統即可解決這個問題
如果能理解這篇文章的所有內容,就能大致上理解編碼是怎麼一回事,Unicode 是什麼東西,UTF-8 又是什麼東西,以及為什麼會有亂碼,又該如何解決。
實際上,編碼的發展歷史遠比這篇文章講述的更為複雜,例如說在 ASCII 之後還出現了 ISO-8859 這個標準來存一些歐洲語系的字元(例如說 Æ),以及除了 UTF-32 以外還有 UTF-16,以及著名的 BOM(Byte-Order Mark)字元,這些比較細節的歷史在文章中都刻意沒有提及。
而 Unicode 這個規範其實也沒這麼簡單,在裡面還定義了一大堆東西跟一些方法論,以及一堆的專有名詞,這些也都沒有提到。甚至對於「一個字」的定義可能也比你想像中複雜一些。
這篇文章的目的是希望沒有技術背景的讀者們也能大概理解編碼是怎麼一回事,因此省略了許多我認為不影響理解的細節,以「讓讀者理解為什麼會這樣發展」為首要目標。如果內容有明顯錯誤,再麻煩留言跟我說。
最後,如果你對編碼的歷史有興趣,或是對實際上電腦到底要怎麼儲存,底下附上我在寫這篇文章以前參考過的一些資料,希望對你有幫助。
- 文字編碼二三事
- 每個軟體開發者都絕對一定要會的Unicode及字元集必備知識(沒有藉口!)
- 工程師一定要懂的 Text Encoding
- UTF-8 遍地开花
- 细说:Unicode, UTF-8, UTF-16, UTF-32, UCS-2, UCS-4
- Unicode 官網
(附註:前幾段的標題靈感來自於 Dcard 調查局的影片,裡面常出現這種押韻的句子,認真想過之後發現寫那些文案的人真厲害)